![]()
Einführung
Schnellstart
XTC im
Detail
Technische Anmerkungen
XTC (Xml Tree Compare) ist ein Differenzwerkzeug für XML-
Dateien. Der Zweck des Programms ist es, als
'Änderungserkennungswerkzeug' für zwei Versionen eines Dokuments
(eine alte und eine neue Version beispielsweise) eingesetzt zu
werden.
Der Vergleichsprozess ist so generisch wie möglich konzipiert.
Die einzige Voraussetzung ist die Wohlgeformtheit der XML-Dokumente.
Es kann daher jedes von XML abgeleitete Format wie SVG, XVL etc.
verglichen werden. Das Ergebnis des Vergleichsprozesses wird in eine
Datei geschrieben (Ergebnisdatei). Zusätzlich steht eine interaktive graphische
Darstellung (Visualisierung) als Baumstruktur zur Verfügung.
XTC ist geeignet um:
eine Ergebnisdatei im XML-Format
zu erzeugen, die anschließend weiterverarbeitet (z.B. mit XSLT)
werden kann
(siehe auch http://xmldifftool.com/xtc_xslt_de.html).
ein Vergleichsergebnis unmittelbar in der Visualisierung zu betrachten.
für große Dateien oder sehr rechenintensive Konstellationen länger dauernde Vergleichsprozesse mit der Server-Version durchzuführen. Die Dateigröße ist dabei nur durch den verfügbaren Arbeitsspeicher des Rechners begrenzt.
XTC kann in andere Prozesse integriert werden, indem die Server-Version wie ein Batch-Prozess aufgerufen wird.
A) GUI-Version:
1. Starten Sie XTC mit einem Doppelklick auf
das Programmsymbol oder durch den Aufruf im 'Programme'-Menü von
Windows. Das XTC Hauptfenster erscheint. Wählen Sie zwei XML-Dateien
mittels der Schaltflächen 'XML Datei 1' und 'XML Datei 2' aus. Die
Dateipfade erscheinen links der beiden Schaltflächen in den weißen
Editboxen.
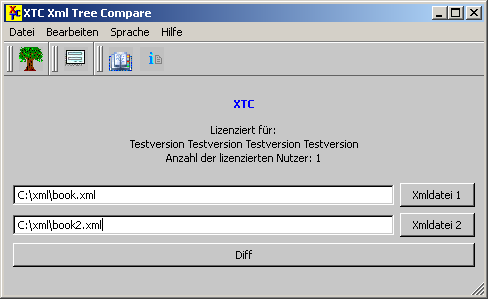
2. Drücken Sie die große Schaltfläche 'Diff'.
3. Je
nach Größe der beiden Dateien und der Hardware kann der
Vergleichsprozess einige Sekunden dauern. Dabei verwandelt sich der
Mauszeiger in eine Sanduhr.
4. Eine Messagebox informiert Sie,
sobald der Vergleichsvorgang abgeschlossen ist.
5. Nach
Beendigung des Vergleichsprozesses kann das Ergebnis durch Druck auf
den Button ganz links in der Werkzeugleiste (Baumsymbol) visualisiert
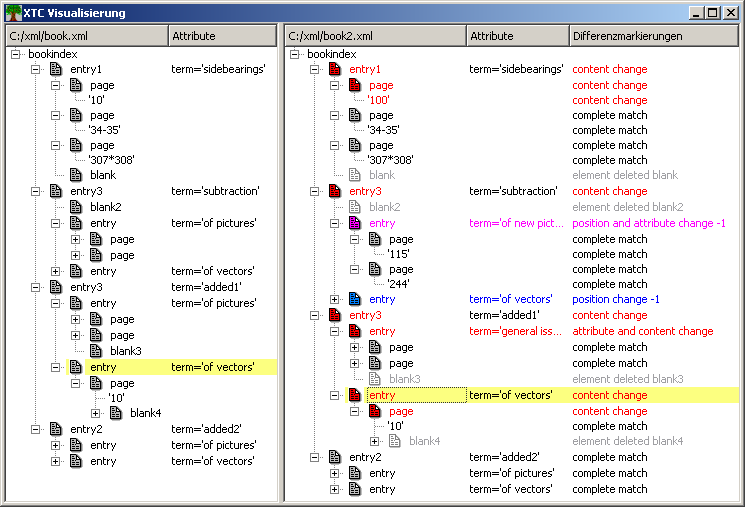
werden. Ein separates Fenster öffnet sich und zeigt die Struktur der
ersten XML-Datei auf der linken, die Struktur der zweiten XML-Datei
einschließlich der Differenzmarkierungen auf der rechten Seite. Die Visualisierung
verfügt über eine interaktive Funktionalität: wird ein Element in einem der
Bäume selektiert, werden das korrespondierende Element im anderen Baum und
das selektierte Element selbst farbig hervorgehoben.
B) Kommandozeilenversion:
1. Öffnen Sie eine Shell
(DOS-Box auf Windows) und wechseln Sie in das Verzeichnis der
XTC-Programmdatei.
2. Tippen Sie 'xtc.exe xmlfile1 xmlfile2
-batch' ein. Dabei ist 'xmlfile1' der Pfad zur ersten XML-Datei,
'xmlfile2' der Pfad zur zweiten XML-Datei.
3. Je nach Dateigrößen
und Hardware dauert der Vergleichsvorgang einige Sekunden.
4.
Nach Beendigung des Vergleichsprozesses befindet sich die
Ergebnisdatei im Verzeichnis der zweiten XML-Datei. Falls Sie dort
keine Ergebnisdatei finden sollten, sehen Sie in der
Konfigurationsdatei (xtc_cfg.xml im aktuellen Verzeichnis oder in
Ihrem Home-Verzeichnis) nach dem Eintrag <writeresultfile>.
Dieser muss so
aussehen:
<xtcparam_bool name="writeresultfile">1</xtcparam_bool>.
Ansonsten
prüfen Sie, ob es Hinweise auf Fehler in der Logdatei gibt
(xtclog.txt).
Beispiel für eine Ergebnisdatei (Ausschnitt):

Das Vergleichen von XML-Dokumenten kann vielfältig motiviert sein. Beispielsweise möchte man schnell und auf einen Blick sehen, was sich an einem Dokument in Bezug auf seine Vorgängerversion geändert hat. Oder die Änderungen sollen bei der Weiterverarbeitung des Dokuments in einer formatierten Version kenntlich gemacht werden. Ebenso kann es aus Gründen der Qualitätssicherung notwendig sein, Änderungen die per Augenschein nur schwer zu finden sind, z.B. an Zeichnungen im SVG-Format, zu protokollieren.
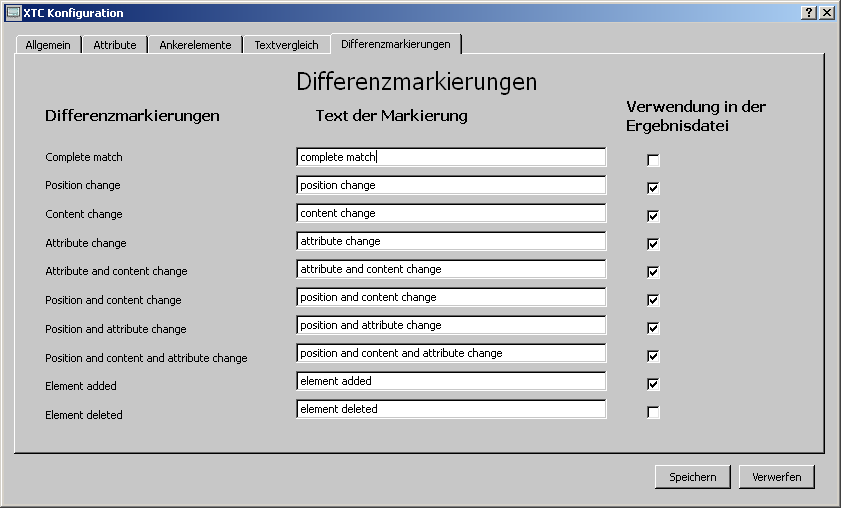
Erkannte Änderungen werden in der Ergebnisdatei mit
Differenzmarkierungen gekennzeichnet. Eine Differenzmarkierung ist
eine Processing Instruction die das Vergleichsergebnis für das
direkt nachfolgende XML-Element beschreibt. Jede erkannte Änderung
wird mit einer der folgenden zehn Differenzmarkierungen versehen:
complete match
position change
content change
attribute
change
attribute and content change
position and content
change
position and attribute change
position and content and
attribute change
element added
element deleted
Vier
davon (position change, position and content change, position and
attribute change, position and content and attribute change) zeigen
an, dass das Element seine Position geändert hat. Die Distanz der
Positionsänderung wird durch eine Zahl an der Differenzmarkierung
angezeigt. Eine Zahl größer Null bedeutet eine Positionsänderung
'vorwärts' ('nach unten'), d.h. die Entfernung zum Elternelement hat
sich vergrößert (z.B. weil oberhalb ein neues Element eingeschoben
wurde). Eine negative Zahl zeigt an, dass sich das Element nun näher
an seinem Elternelement befindet (z.B. weil vorher ein Element
gelöscht wurde).
Beispiel:
Datei
A:
<parent>
<one/>
<two/>
<three/>
</parent>
file
B:
<parent>
<one/>
<two/>
<hundred/>
<three/>
</parent>
Das
Ergebnis lautet::
<parent>
<one/>
<two/>
<?XTC
element added?>
<hundred/>
<?XTC position change
1?>
<three/>
</parent>
(Die 'complete
match'-Markierungen wurden der Einfachheit halber hier weggelassen)
Die Differenzmarkierungen selbst (hier <?XTC element added?>)
zählen natürlich nicht bei der Ermittlung der Positionsänderung,
da sie ja kein inhaltlicher Bestandteil der Datei sind. Andere
(nicht-XTC) Processing Instructions dagegen zählen als normale
Elemente.
Die Differenzmarkierungen werden genauso in der
Visualisierung verwendet.
XTC wurde als generisches Werkzeug konzipiert um möglichst
universell verwendbar zu sein. Wohlgeformtheit der XML-Dateien ist
dabei die einzige Voraussetzung. Für den jeweiligen Anwendungsfall
muss XTC daher konfiguriert werden. Der folgende Text beschreibt die
Konfigurationsmöglichkeiten.
Hinweis: Die folgende
Beschreibung geht davon aus, dass Sie die GUI-Version verwenden.
Falls Sie mit der Kommandozeilenversion arbeiten, müssen Sie die
Konfigurationsdatei xtc_cfg.xml bearbeiten. Diese befindet sich im
aktuellen Verzeichnis oder in Ihrem Home-Verzeichnis. XTC sucht erst
im aktuellen Verzeichnis nach der Konfigurationsdatei und dann (wenn
nichts gefunden wurde) im Home-Verzeichnis des Anwenders.
Starten
Sie XTC (siehe Schnellstart). Der zweite Button in der Werkzeugleiste
(oder Menü Bearbeiten->Konfiguration) öffnet den
Konfigurationsdialog. Dieser besteht aus fünf Reitern ('Allgemein',
'Attribute', 'Ankerelemente', 'Textvergleich' und 'Differenzmarkierungen').
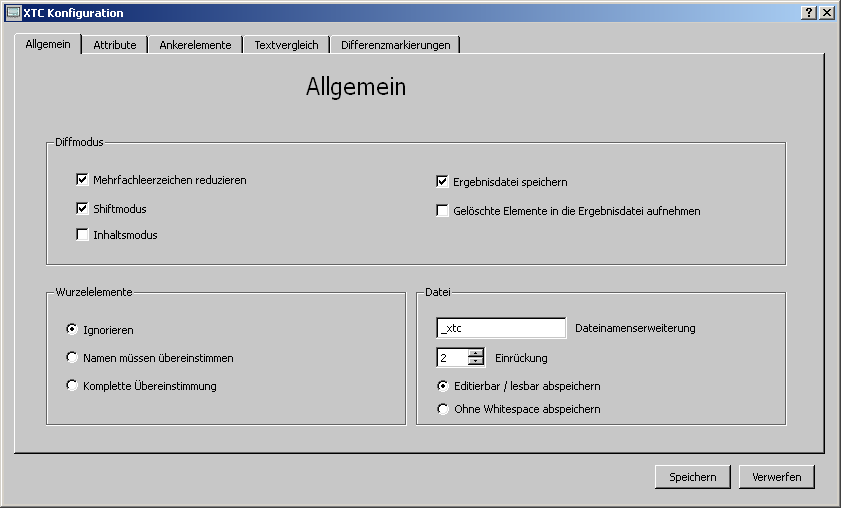
Die Gruppe 'Diffmodus' definiert die grundlegenden Einstellungen für den Vergleichsvorgang:
Mehrfachleerzeichen reduzieren: Reduziert mehrfach hintereinander stehende Leerzeichen zu einem und eliminiert Wagenrücklaufzeichen (CR) und Tabs in Texten. Sinnvoll ist das vor allem auch dann, wenn XML-Editoren o.ä. eigenmächtig Leerzeichen einfügen. Hinweis: Diese Option betrifft den Vergleichsvorgang, die Visualisierung verwendet diese Option immer.
Shiftmodus: Es kann Situationen
während des Vergleichsprozesses geben, in denen eine eindeutige
Elementzuordnung nicht möglich ist. Das ist der Fall, wenn
gleichnamige Elemente des gleichen Elternknotens sowohl ihre
Positionen vertauscht als auch ihre Inhalte geändert haben. Nicht
immer kann dann erkannt werden, ob es sich um ein verändertes
(Position + Inhalt) oder um ein neu hinzugefügtes Element handelt
(Das ist auch 'per Augenschein' nicht in allen Fällen ersichtlich).
Der Shiftmodus ordnet dann gleichnamige Elemente nach dem
'Kürzeste-Entfernung'-Algorithmus einander zu. Das kann in manchen
Fällen zu unerwünschten Ergebnissen führen. Ohne Shiftmodus
werden solche Elemente als 'added' gekennzeichnet (das entsprechende
Element in der Vergleichsdatei wird als 'deleted' gekennzeichnet).
Im Abschnitt 'Ankerelemente' wird ein anderer Lösungsweg für
diese Problematik aufgezeigt.
Inhaltsmodus: Bei aktiviertem Inhaltsmodus versucht das
Programm, die korrekte Zuordnung der Elemente zueinander durch eine
Ähnlichkeitsanalyse der Textinhalte zu erreichen. Text ist dabei
der Inhalt aller Textknoten unterhalb des betreffenden Elements
(ohne Attribute). Die Länge des dadurch ermittelten Textes ist
durch den 'max'-Parameter der Spinbox begrenzt.
Beispiel:
Datei
A:
<para>etwas Text</para>
<para>alter
Abschnitt</para>
<para>viele verschiedene
Neuigkeiten</para>
Datei B:
<para>neuer
Abschnitt</para>
<para>viele und verschiedene
Neuigkeiten</para>
<para>etwas Text</para>
Im
Beispiel gibt es je drei gleichnamige Elemente mit je einem
Textelement. Dabei haben sich in Datei B die Elementreihenfolge und
einTeil der Texte geändert. Der Algorithmus vergleicht nun die
Textinhalte auf Ähnlichkeit und findet so die korrekte
Zuordnung:
<para>neuer Abschnitt</para>
---------------------------- <para>alter
Abschnitt</para>
<para>viele und verschiedene
Neuigkeiten</para> --- <para>viele verschiedene
Neuigkeiten</para>
<para>etwas Text</para>
---------------------------------- <para>etwas
Text</para>
Hinweis: Manchmal führt der Inhaltsmodus
zu einem unerwarteten (d.h. unerwünschten aber der Konfiguration
nach korrekten) Ergebnis. In einem solchen Fall sollte der
Inhaltsmodus deaktiviert werden.
Hinweis: Bei aktiviertem
Inhaltsmodus kann grundsätzlich jedes Element (sofern es nicht
anders zugeordnet werden kann) vom Inhaltsmodus analysiert werden.
Dabei wird der gesamte Teilbaum (subtree) analysiert, was zu längeren Rechenzeiten führen kann.
Ergebnisdatei speichern: Falls man nur
an der Visualisierung interessiert ist, kann man hier das Schreiben
der Ergebnisdatei ausschalten.
Hinweis: Bei großen Dateien kann
das Schreiben der Ergebnisdatei in das Dateisystem viel Zeit in
Anspruch nehmen, unter Umständen mehr als der Vergleichsprozess
selbst.
Gelöschte Elemente in die Ergebnisdatei aufnehmen: Elemente
die in Datei A aber nicht in Datei B vorkommen, werden als gelöscht
markiert. Sollen diese auch in der Ergebnisdatei erscheinen, ist die
Checkbox zu aktivieren.
Hinweis: Dies kann unter Umständen (je
nach DTD oder Schema) dazu führen, dass die Ergebnisdatei nicht
mehr valide ist!
Wurzelelemente:
XML Wurzelelemente legt fest, wie XTC die Wurzelelemente der
beiden XML-Dateien behandeln soll (da diese nicht Teil des
Vergleichvorgangs sind).
Diese Option ist normalerweise nur im Batch-Betrieb von Bedeutung.
Ignorieren: Mit dieser Option werden die Wurzelelemente nicht verglichen
Namen müssen übereinstimmen: Hier müssen die beiden Wurzelelemente den gleichen Namen haben
Komplette Übereinstimmung: Hier müssen sowohl die beiden Namen als auch die Attribute der Wurzelelemente gleich sein. Die Reihenfolge der Attribute darf allerdings verschieden sein.
Der Abschnitt 'Datei' definiert Eigenschaften der Ergebnisdatei
Dateinamensergänzung: Legt eine Zeichenfolge fest, die in den Namen der Ergebnisdatei einfließt. Die Ergebnisdatei ist ja zunächst eine Kopie von Datei B, muss aber, um ein Überschreiben zu verhindern, einen anderen Namen bekommen. Beispiel: Der Name von Datei B sei 'book2.xml' und die Dateinamenserweiterung sei _xtc, dann heißt die Ergebnisdatei 'book2_xtc.xml'.
Einrückung: Gibt die Anzahl der Zeichen an, um die verschachtelte Elemente in der Ergebnisdatei eingerückt werden (gilt nur für 'Editierbar / lesbar abspeichern').
Editierbar / lesbar abspeichern: Schreibt jedes XML-Element
in eine eigene Zeile, verwendet Einrückung und erzeugt damit eine
(menschen-)lesbare Datei.
'Ohne Whitespace abspeichern': Erzeugt
eine Ergebnisdatei ohne Leerzeichen und Zeilenschaltungen zwischen
den Elementen. Dies erleichtert die automatisierte
Weiterverarbeitung der Datei (z.B. mit XSLT).
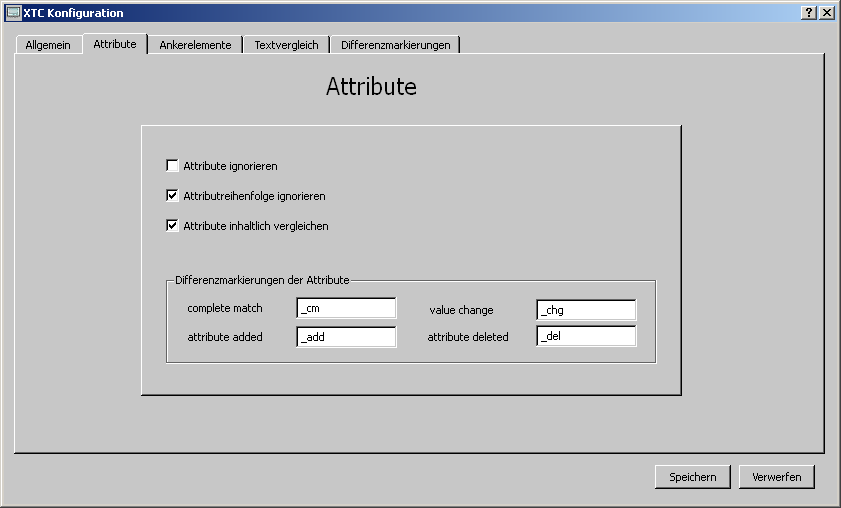
Attribute ignorieren: Schließt Attribute vom Vergleichsvorgang aus.
Attributreihenfolge ignorieren: Falls ausgewählt, wird die Reihenfolge der Attribute nicht als Änderungskriterium angesehen.
Attribute inhaltlich vergleichen:
Falls ausgewählt, werden die Attribute eines Elements mit denen des Vergleichselements einer eigenen Vergleichsprozedur unterzogen.
Jedes Attribut wird daraufhin untersucht, ob es
unverändert ist (complete match)
seinen Inhalt geändert hat (value change)
neu hinzugekommen ist (attribute added) oder
gelöscht worden ist (attribute deleted).
Dazu werden die Attributnamen um die bei 'Differenzmarkierungen der Attribute'
angegebenen Zeichen ergänzt.
Im Fall einer Inhaltsänderung (value change) wird der Attributwert zusätzlich
einem Textvergleich unterzogen (siehe auch Reiter Textvergleich, die Einstellungen für LCSS-Mindestlänge und Textmarkierungen werden hier auch verwendet).
Durch die Definition von Ankerelementen kann man dem Programm Kriterien an die Hand geben, um im Fall von Mehrfachänderungen (Position und Inhalt) und Namensgleichheit das korrekte Vergleichselement zu finden. Anker geben dem Programm zusätzliche Information, die aus den XML-Dateien selbst in solcher Form nicht hervorgeht (das 'Meta'-Wissen des Anwenders). Ein Ankerelement ist ein XML-Elementname oder ein Attributname dessen Inhalt konstant bleibt, auch wenn der Rest des Dokuments sich ändert. Der Anker dient so zur Identifizierung einander zugehöriger Elemente in den beiden Dateien.
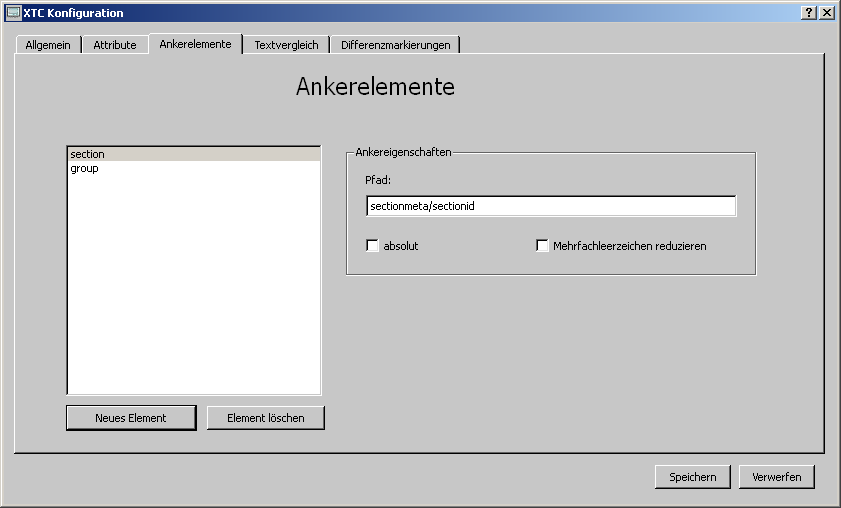
Beispiel:
Datei
A:
<chapter>
<section>
<sectionmeta>
<sectionid>3</sectionid>
<sectionname>.....</sectionname>
</sectionmeta>
<para>....</para>
...
</section>
Datei
B:
<section>
<sectionmeta>
<sectionid>4</sectionid>
<sectionname>.....</sectionname>
</sectionmeta>
<para>....</para>
...
</section>
<section>
...
</section>
</chapter>
Hier
kann das Element <sectionid> als Anker definiert werden. Wenn
sich nun die Reihenfolge der 'section'-Elemente und ebenso ihr Inhalt
('sectionid' natürlich ausgenommen) ändert, findet der Algorithmus
die richtige Zuordnung der 'section'-Elemente indem die Inhalte ihrer
'sectionid'-Kindelemente verglichen werden. Der Vergleich ist dabei
ein Textvergleich der auch die Textinhalte (ohne Attribute) aller
Kindelemente (den gesamten Teilbaum) miteinschließt.
Die
Ankerdefinition in der Konfiguration sähe in diesem Beispiel so aus:
section sectionmeta/sectionid
(siehe Abbildung))
Der
Pfad zum Anker wird mit / (Schrägstrich) als Trennungszeichen
angegeben. Auch Attribute können als Anker definiert werden:
Beispiel:
<chapter>
<section>
<sectionmeta
id=”3”>
<sectionname>.....</sectionname>
</sectionmeta>
<para>....</para>
...
</section>
<section>
<sectionmeta
id=”4”>
<sectionname>.....</sectionname>
</sectionmeta>
<para>....</para>
...
</section>
<section>
...
</section>
</chapter>
Die
Ankerdefinition wäre hier:
section sectionmeta/@id
'@' zeigt
an, dass der Anker ein Attribut ist.
Um ein neues
Ankerelement zu definieren, öffnet die Schaltfläche 'Neues Element'
eine kleine Dialogbox.
Dort kann der Elementname und der Pfad zum
Anker eingetragen werden.
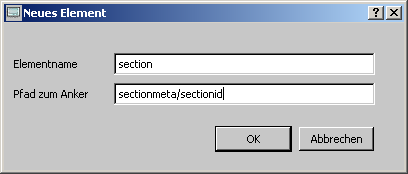
Für ein XML-Element sollte nur ein Anker definiert werden. Gibt es mehr als einen Anker, wird nur der zuletzt definierte verwendet. Die Ankerfunktionalität ist auch dann wirksam, wenn 'Attribute ignorieren' eingeschaltet ist. Ankerelemente die definiert aber nicht in der XML-Datei zu finden sind, werden ignoriert.
Anker werden definiert, um dem Programm zusätzliche
Identifikationsmerkmale für die Elemente zu geben. Bei Elementen für
welche ein Anker definiert wurde, die aber dennoch nicht durch den
Ankeralgorithmus zugeordnet werden können, kann man zwei Ursachen
unterscheiden:
1. Es gab keine Übereinstimmung des Ankerinhalts
mit dem eines anderen solchen Elements.
2. Der definierte Anker
ist bei diesem Element (aus welchen Gründen auch immer) nicht
vorhanden.
Falls die 'absolut'-Checkbox aktiviert ist, werden
Elemente mit vorhandenem Anker aber ohne Übereinstimmung als 'added'
bzw. 'deleted' gekennzeichnet, während Elemente ohne den definierten
Anker vom Ankeralgorithmus nicht gekennzeichnet werden. Mit
deaktivierter Checkbox bleiben solche Elemente ohne Unterschied in
ihrem vorherigen Zustand.
Ist ein Element als Anker definiert dann ist der Ankerinhalt der Elementinhalt, und zwar der gesamte darunter befindliche Teilbaum, der als Textkonkatenation ausgewertet wird. Bei aktivierter Checkbox werden mehrfach hintereinander stehende Leerzeichen zu einem reduziert und Wagenrücklaufzeichen (CR) und Tabs eliminiert. Sinnvoll ist das vor allem dann, wenn XML-Editoren o.ä. eigenmächtig Leerzeichen einfügen.
Textelemente die sich inhaltlich geändert haben, können noch
einem zusätzlichen Textvergleich unterzogen werden. 'Textvergleich
ein / aus' schaltet die Funktionalität ein oder aus.
Der
Algorithmus teilt den Textinhalt in drei Kategorien ein:
unverändert (wird nicht gekennzeichnet)
hinzugefügt (gekennzeichnet mit der Zeichenfolge von 'Beginn eines hinzugefügten Textes' / 'Ende eines hinzugefügten Textes')
gelöscht (gekennzeichnet mit der Zeichenfolge von 'Beginn eines gelöschten Textes' / 'Ende eines gelöschten Textes')
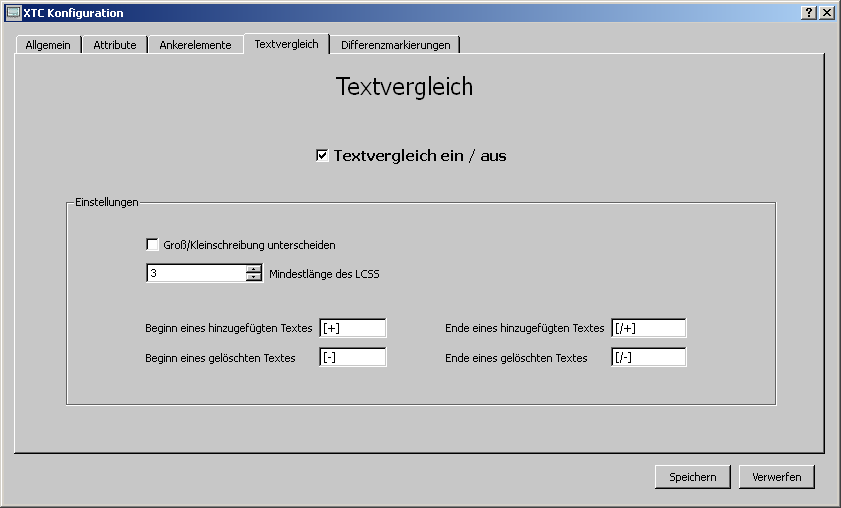
Einstellungen:
Groß/Kleinschreibung beachten: Wenn aktiviert, wird beim Vergleich Groß- und Kleinschreibung unterschieden (Der allgemeine Vergleich der XML-Elemente unterscheidet Groß- und Kleinschreibung).
Mindestlänge des LCSS: Der Textvergleich basiert im Kern auf
einer Variante des 'Longest common substring'-Algorithmus (LCSS).
Werden zwei Texte verglichen, finden sich oft viele gemeinsame
Teilstrings, die sehr verschiedener Länge sind (im Extremfall nur
ein Zeichen). Der Parameter gibt nun an, wie lang ein gemeinsamer
Teilstring mindestens sein muss, um ein brauchbares Ergebnis zu
erzielen. Beispiel:
a)
Text 1: “xml” Text 2: “xtc”
falls
'Mindestlänge des LCSS' auf '1' (Mindestwert) gesetzt ist, sieht
das Ergebnis so aus:
x[-]ml[/-][+]tc[/+]
“x” ist
der LCSS und ist unverändert. “ml” wurde gelöscht, “tc”
wurde hinzugefügt.
falls 'Mindestlänge des LCSS' auf '2'
gesetzt ist, ist das Ergebnis:
[-]xml[/-][+]xtc[/+]
Kein
LCSS gleich oder größer 2 ist vorhanden, also wird der gefundene
mit Länge 1 ('x') nicht verwendet.
b)
Text 1: “Nudeln”
Text 2: “Salat”
Falls 'Mindestlänge des LCSS' auf '1'
gesetzt ist:
[-]Nude[/-][+]Sa[/+]l[-]n[/-][+]at[/+]
Falls
'Mindestlänge des LCSS' auf '2' (oder mehr) gesetzt ist:
[-]Salat[/-][+]Nudeln[/+]
Für Texte in natürlicher Sprache ist eine Mindestlänge des
LCSS von 3 oder mehr sinnvoll.
Die Markierungen für
hinzugefügten / gelöschten Text können definiert werden,
vorgegebene Werte sind:
[+] Beginn eines hinzugefügten Textes
[/+] Ende eines hinzugefügten Textes
[-] Beginn eines gelöschten Textes
[/-] Ende eines gelöschten Textes
Hier können eigene Zeichenfolgen für die Differenzmarkierungen festgelegt werden. Zudem kann für jede Markierung definiert werden, ob sie in der Ergebnisdatei Verwendung finden soll oder nicht. Jede Differenzmarkierung kann damit ein- oder ausgeschaltet werden.
XTC ist in C++ unter Verwendung der QT-Bibliothek von Nokia programmiert.
Dabei wurde eine eigens
konzipierte, spezielle XML-API entwickelt, um Unabhängigkeit,
Flexibilität und sehr gute Performance zu ermöglichen.
Unterstützte Betriebssysteme sind derzeit Windows 2000, XP, Vista, Windows 7.
Versionen für andere
Betriebssysteme können auf Anfrage bereitgestellt werden.
http://xmldifftool.com
Fragen und Anregungen:
info@xmldifftool.com
Copyright ©
2009-2012 Martin Achtziger